C#에서 PDF 파일 사용하기
C#에서 Adobe PDF 파일을 사용하기 위해서는 iTextSharp, PdfSharp, Aspose.PDF for .NET (유료) 등과 같은 3rd Party 라이브러리를 사용한다. 이 아티클에서는 이 중 많이 사용되는 iTextSharp에 대해 몇가지 기초 기능들을 살펴본다.
iTextSharp의 최신 버전은 여러 유용한 기능들을 가지고 있는 반면, AGPL 라이슨스를 가지고 있어서 사용시 소스코드를 Release 해야 하는 단점이 있다. 이러한 점을 피하고자 한다면 이전 버전으로 LGPL 라이슨스를 갖는 iTextSharp를 사용할 수 있는데, LGPL 버전은 최신 추가 기능들을 사용할 수 없는 단점이 있다.
iTextSharp의 LGPL과 AGPL 버전은 아래와 같이 Nuget 패키지로 간단히 설치할 수 있다.
iTextSharp의 최신 버전은 여러 유용한 기능들을 가지고 있는 반면, AGPL 라이슨스를 가지고 있어서 사용시 소스코드를 Release 해야 하는 단점이 있다. 이러한 점을 피하고자 한다면 이전 버전으로 LGPL 라이슨스를 갖는 iTextSharp를 사용할 수 있는데, LGPL 버전은 최신 추가 기능들을 사용할 수 없는 단점이 있다.
iTextSharp의 LGPL과 AGPL 버전은 아래와 같이 Nuget 패키지로 간단히 설치할 수 있다.
예제
// LGPL iTextSharp 를 설치할 경우 (v4.1.6)
PM> Install-Package iTextSharp-LGPL
// 최신 AGPL iTextSharp 를 설치할 경우 (v5.*)
PM> Install-Package iTextSharp
PM> Install-Package iTextSharp-LGPL
// 최신 AGPL iTextSharp 를 설치할 경우 (v5.*)
PM> Install-Package iTextSharp
C#에서 PDF 파일 생성하기
iTextSharp를 사용해서 C#에서 PDF 파일을 생성하기 위해서는 iTextSharp.text.Document 클래스와 iTextSharp.text.pdf.PdfWriter 클래스를 사용한다. 먼저 Document 클래스의 객체를 생성하고 생성하고자 하는 파일의 파일스트림을 만든 후, 이 두 객체를 PdfWriter.GetInstance( Document객체, 파일스트림객체 ) 메서드에 전달한다. PdfWriter는 Document 객체의 변동부분을 감지하여 이를 파일스트림에 보내는 역활을 하게된다.
다음 Document 객체에서 PDF 문서를 열고, 다양한 Add 메서드들을 사용하여 문서에 내용을 채워넣으면 된다. PDF 문서가 완성되었으면, Document를 닫으면 된다
아래 예제는 simple.pdf 라는 간단한 PDF 파일을 작성해 본 것으로, 제목과 저자 그리고 본문에는 간단한 텍스트를 쓰고 있다. 특히, 한글과 같은 비영어권 문자를 쓸 때에는 아래와 같이 해당 폰트를 지정해야 한다. 아래는 한글을 바탕체 12 사이즈로 출력하는 예이다.
다음 Document 객체에서 PDF 문서를 열고, 다양한 Add 메서드들을 사용하여 문서에 내용을 채워넣으면 된다. PDF 문서가 완성되었으면, Document를 닫으면 된다
아래 예제는 simple.pdf 라는 간단한 PDF 파일을 작성해 본 것으로, 제목과 저자 그리고 본문에는 간단한 텍스트를 쓰고 있다. 특히, 한글과 같은 비영어권 문자를 쓸 때에는 아래와 같이 해당 폰트를 지정해야 한다. 아래는 한글을 바탕체 12 사이즈로 출력하는 예이다.
예제
//using iTextSharp.text;
//using iTextSharp.text.pdf;
// Document 객체 생성
Document doc = new Document(iTextSharp.text.PageSize.LETTER);
// PdfWriter가 doc 내용을 simple.pdf 파일에 쓰도록 설정
PdfWriter wr = PdfWriter.GetInstance(doc, new FileStream("simple.pdf", FileMode.Create));
// Document 열기
doc.Open();
// Document에 내용 쓰기
doc.AddTitle("Simple PDF 생성 예제");
doc.AddAuthor("Alex");
doc.AddCreationDate();
// 영문쓰기
doc.Add(new Paragraph("English : How are you?"));
// 한글쓰기
string batangttf = System.IO.Path.Combine(Environment.GetEnvironmentVariable("SystemRoot"), @"Fonts\BatangChe.TTF");
BaseFont batangBase = BaseFont.CreateFont(batangttf, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
var batang = new iTextSharp.text.Font(batangBase, 12F);
doc.Add(new Paragraph("한글: 안녕하세요?", batang));
// Document 닫기
doc.Close();
//using iTextSharp.text.pdf;
// Document 객체 생성
Document doc = new Document(iTextSharp.text.PageSize.LETTER);
// PdfWriter가 doc 내용을 simple.pdf 파일에 쓰도록 설정
PdfWriter wr = PdfWriter.GetInstance(doc, new FileStream("simple.pdf", FileMode.Create));
// Document 열기
doc.Open();
// Document에 내용 쓰기
doc.AddTitle("Simple PDF 생성 예제");
doc.AddAuthor("Alex");
doc.AddCreationDate();
// 영문쓰기
doc.Add(new Paragraph("English : How are you?"));
// 한글쓰기
string batangttf = System.IO.Path.Combine(Environment.GetEnvironmentVariable("SystemRoot"), @"Fonts\BatangChe.TTF");
BaseFont batangBase = BaseFont.CreateFont(batangttf, BaseFont.IDENTITY_H, BaseFont.EMBEDDED);
var batang = new iTextSharp.text.Font(batangBase, 12F);
doc.Add(new Paragraph("한글: 안녕하세요?", batang));
// Document 닫기
doc.Close();
C#에서 PDF 파일 읽기
iTextSharp를 사용해서 PDF 파일을 읽기 위해서는 iTextSharp.text.pdf.PdfReader 클래스를 사용한다. PDF는 여러 페이지들로 구성되는데, PdfReader 객체의 NumberOfPages 속성을 사용하여 총 페이지수를 구할 수 있고, 각 페이지의 내용을 GetPageContent() 메서드를 써서 Raw 데이타를 바이트 배열로 구할 수 있다. 이 Raw 데이타에는 PDF에서 사용하는 위치, 포맷 등의 정보들이 함께 들어가 있다.
iTextSharp LGPL 버전의 경우 PDF 페이지 내용을 해석해서 텍스트만을 리턴하는 기능이 없으므로, 텍스트 내용만을 발췌하기 위해서는 iTextSharp AGPL 버전을 사용하는 것이 효율적이다. iTextSharp AGPL의 경우 iTextSharp.text.pdf.parser 네임스페이스(주: 여러 parser 기능 제공)에 PdfTextExtractor 라는 클래스가 있는데, PdfTextExtractor.GetTextFromPage() 정적 메서드를 사용하면 특정 페이지 안의 텍스트만을 발췌할 수 있다.
아래 예제는 iTextSharp LGPL 버전과 iTextSharp AGPL 버전을 각각 사용하여 PDF 파일로부터 텍스트 데이타를 얻어내는 예이다.
iTextSharp LGPL 버전의 경우 PDF 페이지 내용을 해석해서 텍스트만을 리턴하는 기능이 없으므로, 텍스트 내용만을 발췌하기 위해서는 iTextSharp AGPL 버전을 사용하는 것이 효율적이다. iTextSharp AGPL의 경우 iTextSharp.text.pdf.parser 네임스페이스(주: 여러 parser 기능 제공)에 PdfTextExtractor 라는 클래스가 있는데, PdfTextExtractor.GetTextFromPage() 정적 메서드를 사용하면 특정 페이지 안의 텍스트만을 발췌할 수 있다.
아래 예제는 iTextSharp LGPL 버전과 iTextSharp AGPL 버전을 각각 사용하여 PDF 파일로부터 텍스트 데이타를 얻어내는 예이다.
예제
//
// iTextSharp LGPL 사용시 Raw 데이타를 수동으로 처리해야
//
PdfReader reader = new PdfReader("fw4.pdf");
for (int pageNo = 1; pageNo <= reader.NumberOfPages; pageNo++)
{
byte[] rawBytes = reader.GetPageContent(pageNo);
byte[] utf8Bytes = Encoding.Convert(Encoding.Default, Encoding.UTF8, rawBytes);
string pageText = Encoding.UTF8.GetString(utf8Bytes);
Debug.WriteLine(pageText);
}
reader.Close();
//
// iTextSharp AGPL 사용시 정확히 Text를 읽어냄
//
PdfReader reader = new PdfReader("fw4.pdf");
for (int pageNo = 1; pageNo <= reader.NumberOfPages; pageNo++)
{
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
string extractedText = PdfTextExtractor.GetTextFromPage(reader, pageNo, strategy);
byte[] utf8Bytes = Encoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(extractedText));
string pageText = Encoding.UTF8.GetString(utf8Bytes);
Debug.WriteLine(pageText);
}
reader.Close();
// iTextSharp LGPL 사용시 Raw 데이타를 수동으로 처리해야
//
PdfReader reader = new PdfReader("fw4.pdf");
for (int pageNo = 1; pageNo <= reader.NumberOfPages; pageNo++)
{
byte[] rawBytes = reader.GetPageContent(pageNo);
byte[] utf8Bytes = Encoding.Convert(Encoding.Default, Encoding.UTF8, rawBytes);
string pageText = Encoding.UTF8.GetString(utf8Bytes);
Debug.WriteLine(pageText);
}
reader.Close();
//
// iTextSharp AGPL 사용시 정확히 Text를 읽어냄
//
PdfReader reader = new PdfReader("fw4.pdf");
for (int pageNo = 1; pageNo <= reader.NumberOfPages; pageNo++)
{
ITextExtractionStrategy strategy = new SimpleTextExtractionStrategy();
string extractedText = PdfTextExtractor.GetTextFromPage(reader, pageNo, strategy);
byte[] utf8Bytes = Encoding.Convert(Encoding.Default, Encoding.UTF8, Encoding.Default.GetBytes(extractedText));
string pageText = Encoding.UTF8.GetString(utf8Bytes);
Debug.WriteLine(pageText);
}
reader.Close();
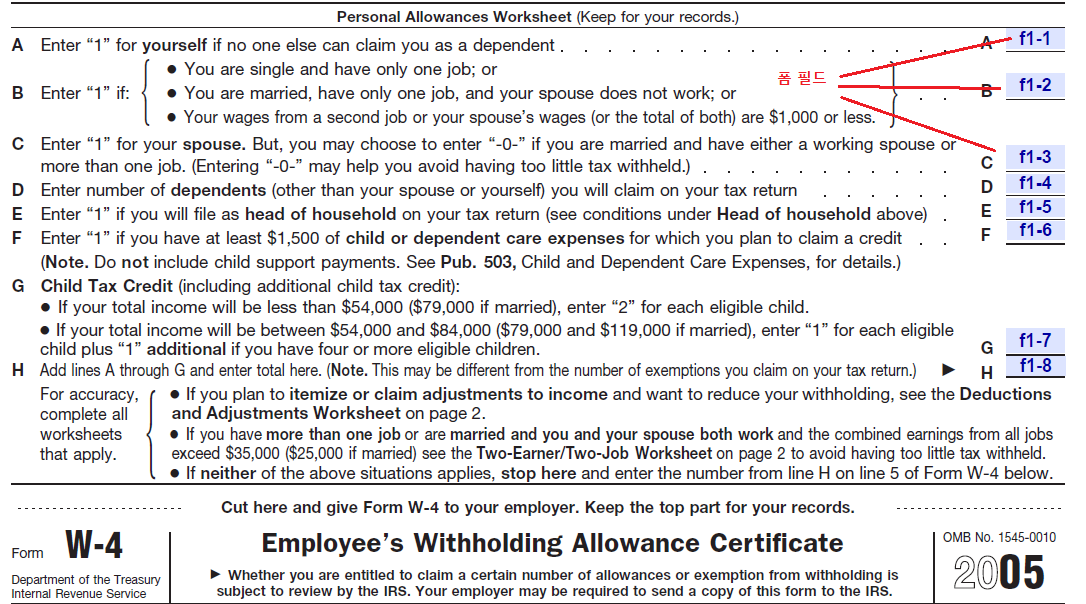
C#에서 PDF 폼 필드 작성
iTextSharp에서 기존 PDF 를 일부 수정하기 위하여 PdfStamper 클래스를 사용한다. PdfStamper 클래스는 새로운 페이지 추가, 첨부 파일 추가, 코멘트 추가, JavaScript 추가, 북마크 지정, 폼 필드 수정 등 다양한 기능을 제공한다.
PDF 파일 중 폼 필드(Form Field)를 갖는 파일이 있는데, PdfStamper 클래스를 사용하여 이들 폼 필드들을 읽거나 수정할 수 있다. PdfStamper는 입력 PDF 파일을 지정하는 PdfReader 객체와 출력 PDF 파일을 지정한 파일스트림을 입력 받아 PdfStamper 객체를 생성한다. PdfStamper 객체가 닫히면 PdfReader는 자동으로 닫히게 된다.
PDF의 폼 필드는 PdfStamper 객체의 AcroFields.Fields 속성에 Hashtable 형태로 저장되어 있다. 이 Hashtable에서 폼 필드의 Key값을 알아내고, 현재 폼 필드의 값을 AcroFields.GetField(키) 메서드를 써서 알아낼 수 있다. 또한, AcroFields.SetField(키, 새값)을 사용하면 해당 폼 필드에 새 값을 넣을 수 있다.
아래 예제는 fw4.pdf (https://www.irs.gov/pub/irs-pdf/fw4.pdf) 파일 안의 폼 필드 정보를 읽고, 폼 필드에 해당 필드명을 써서 새 PDF를 만드는 예이다.
PDF 파일 중 폼 필드(Form Field)를 갖는 파일이 있는데, PdfStamper 클래스를 사용하여 이들 폼 필드들을 읽거나 수정할 수 있다. PdfStamper는 입력 PDF 파일을 지정하는 PdfReader 객체와 출력 PDF 파일을 지정한 파일스트림을 입력 받아 PdfStamper 객체를 생성한다. PdfStamper 객체가 닫히면 PdfReader는 자동으로 닫히게 된다.
PDF의 폼 필드는 PdfStamper 객체의 AcroFields.Fields 속성에 Hashtable 형태로 저장되어 있다. 이 Hashtable에서 폼 필드의 Key값을 알아내고, 현재 폼 필드의 값을 AcroFields.GetField(키) 메서드를 써서 알아낼 수 있다. 또한, AcroFields.SetField(키, 새값)을 사용하면 해당 폼 필드에 새 값을 넣을 수 있다.
아래 예제는 fw4.pdf (https://www.irs.gov/pub/irs-pdf/fw4.pdf) 파일 안의 폼 필드 정보를 읽고, 폼 필드에 해당 필드명을 써서 새 PDF를 만드는 예이다.
예제
// 입력 PDF 파일
PdfReader rdr = new PdfReader("fw4.pdf");
// PdfStamper는 기존 PDF에 일부 내용을 추가할 수 있다.
// 새 fw4out.pdf 파일에 수정된 내용을 저장한다.
FileStream fs = new FileStream("fw4out.pdf", FileMode.Create);
PdfStamper stamper = new PdfStamper(rdr, fs);
// PDF의 폼 필드들 읽기
Hashtable dt = stamper.AcroFields.Fields;
foreach (object k in dt.Keys)
{
// 폼 필드의 키-값 출력
string formKey = k.ToString();
string formValue = stamper.AcroFields.GetField(k.ToString());
Debug.WriteLine(formKey + ":" + formValue);
// 폼 필드 수정. 폼 필드에 폼 필드명을 쓴다
stamper.AcroFields.SetField(k.ToString(), k.ToString());
}
// PdfStamper가 닫히면 연결된 PdfReader도 닫힌다.
stamper.Close();
PdfReader rdr = new PdfReader("fw4.pdf");
// PdfStamper는 기존 PDF에 일부 내용을 추가할 수 있다.
// 새 fw4out.pdf 파일에 수정된 내용을 저장한다.
FileStream fs = new FileStream("fw4out.pdf", FileMode.Create);
PdfStamper stamper = new PdfStamper(rdr, fs);
// PDF의 폼 필드들 읽기
Hashtable dt = stamper.AcroFields.Fields;
foreach (object k in dt.Keys)
{
// 폼 필드의 키-값 출력
string formKey = k.ToString();
string formValue = stamper.AcroFields.GetField(k.ToString());
Debug.WriteLine(formKey + ":" + formValue);
// 폼 필드 수정. 폼 필드에 폼 필드명을 쓴다
stamper.AcroFields.SetField(k.ToString(), k.ToString());
}
// PdfStamper가 닫히면 연결된 PdfReader도 닫힌다.
stamper.Close();